Monitoring with Prometheus读书笔记
原书见:
https://www.safaribooksonline.com/library/view/monitoring-with-prometheus/9780988820289/
摘录了一些内容,稍微整理了下,更详细的内容可以阅读原书.
简介
Prometheus灵感来源于谷歌的borgmon.
他的设计专注于最近发生的事,而不是几个星期几个月前的,默认只保存15天的时间序列.
内置PromQL查询语言,可以方便进行metric查询和定义新的metric.
数据格式
1 | <time series name>{<label name>=<label value>, ...} |
例子:
1 | total_website_visits{site="MegaApp", location="NJ", instance="webserver",job="web"} |
安装
安装过程比较简单,官网下载之后解压即可.
windows下可以使用choco安装:
1 | choco install prometheus |
也可以使用docker运行:
1 | docker run -p 9090:9090 prom/prometheus |
解压后自带一个配置文件,启动时带上文件路径即可:
1 | prometheus --config.file "/etc/prometheus/prometheus.yml" |
(放置在了/etc/prometheus下)
默认跑在9090端口.
监控容器和节点
节点(机器)监控可以使用node exporter.
下载node exporter 解压 复制到可执行中
1 | wget https://github.com/prometheus/node_exporter/releases/download/v0.16.0/node_exporter-0.16.0.linux-amd64.tar.gz |
默认是9100端口,可以通过/metrics访问.
收集的数据较多,不需要的指标可以通过--no-模块名禁用,同时一些没有开启的模块可以通过--模块名开启.
容器监控可以使用cadvisor
1 | docker run \ |
监听在8080端口.
对应的Prometheus配置修改:
1 | scrape_configs: |
(ip等信息写在targets中)
Label
注意改变一个label或增加一个新的label会创建一个新的time series.
对收集的metrics的label进行操作.
可以去掉不必要的metrics和label,增加编辑label.
有两个阶段可以修改:
- relabel_configs:用来修改服务发现过来的元数据label.
- metric_relabel_configs:获得数据存储到磁盘之前操作
如图所示: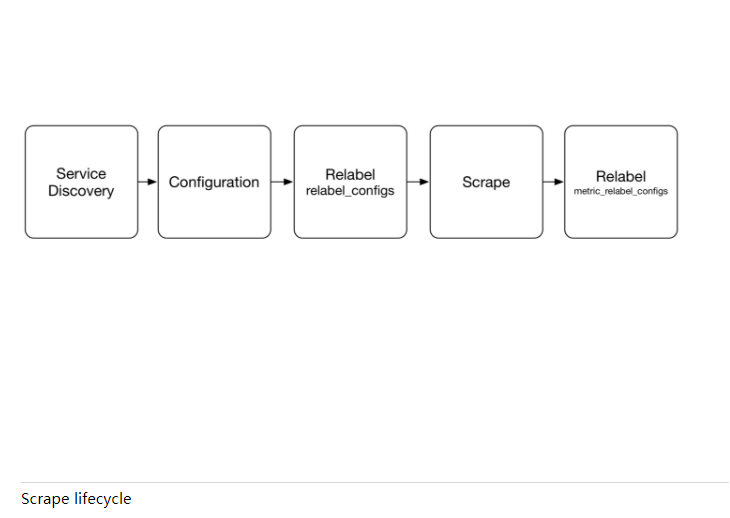
一些配置(和job_name平级):
1 | metric_relabel_configs: |
__name__是metrics的保留label,表示这个metric的名字,这里将这些名字用,拼起来,过滤掉符合正则的名字的metrics.
1 | metric_relabel_configs: |
替换掉id符合正则的内容产生另一个名为container_id的label.
此外有一个honor_labels的参数可以控制替换后的label和现有重名的问题,默认为false,现有的冲突会加上exported_的前缀.设置为true,会忽略该替换的label.
1 | metric_relabel_configs: |
移除掉现有符合正则的label.
Metrics
CPU利用率
使用node_cpu_seconds_total
如图:
计算5min为取样每秒的瞬时利用率
1 | 100 - avg (irate(node_cpu_seconds_total{job="node",mode="idle"}[5m])) by (instance) * 100 |
5m是range vector,表示使用记录的上一个5分钟的数据.
irate是瞬时变化率,适合变化较频繁的metric.
avg是因为有多个metrics(分别是每核的)
CPU饱和度
node_load*
后面的*有1 5 15,表示多少分钟.
该metric和核数有关,查看核数可以使用:
1 | count by (instance)(node_cpu_seconds_total{mode="idle"}) |
内存使用
node_memory_*
列出空闲内存
1 | (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Cached_bytes + node_memory_Buffers_bytes)) / node_memory_MemTotal_bytes * 100 |
内存饱和度
监控paging in和paging out的内存
/proc/vmstat
node_vmstat_pswpin
node_vmstat_pswpout
单位是KB
1 | 1024 * sum by (instance) ( |
算出每分钟的变化量
rate是平均变化率,相比irate适合变化幅度不剧烈的数据.
磁盘使用率
node_filesystem_*
使用率:
1 | (node_filesystem_size_bytes{mountpoint="/"} - node_filesystem_free_bytes{mountpoint="/"}) / node_filesystem_size_bytes{mountpoint="/"} * 100 |
可以用=匹配正则 相对的有!
1 | predict_linear(node_filesystem_free_bytes{job="node"}[1h], 4*3600) < 0 |
通过1h的估计量 看看4h后是否会用完
exporter的可用性监控
可以使用up.
1 | up{job="node"} |
返回1表示node_exporter存活.
持久化Query
除了直接查询,query还可以在其他场合持久化使用:
- Recording rule - 通过query创建新的metrics
- Alerting rules - 生成报警
- Visualization - 可视化
设置prometheus.yml的rules_files块,增加一个新的rule:
1 | rule_files: |
对应的该文件内容如下:
1 | groups: |
配置文件修改后可以使用promtool的对应命令,比如promtool check rules node_rules.yml进行检查.
可以在Prometheus上通过/rules查看: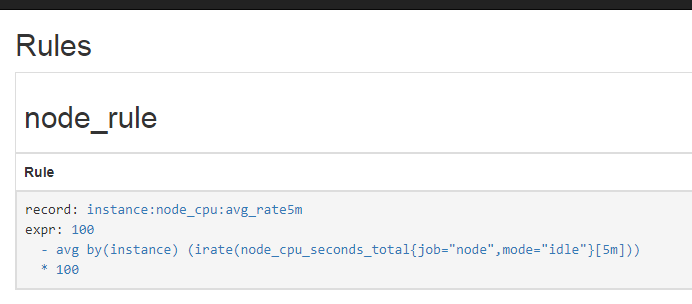
可视化
使用grafana
centos下安装:
1 | wget https://s3-us-west-2.amazonaws.com/grafana-releases/release/grafana-5.2.2-1.x86_64.rpm |
配置在/etc/grafana/grafana.ini.
通过sudo service grafana-server start启动服务.
默认使用3000端口.
默认用户名和密码在配置文件,为admin:admin.
登陆后增加数据源选择Prometheus即可.
然后可以新增dashboard,配置对应的查询:
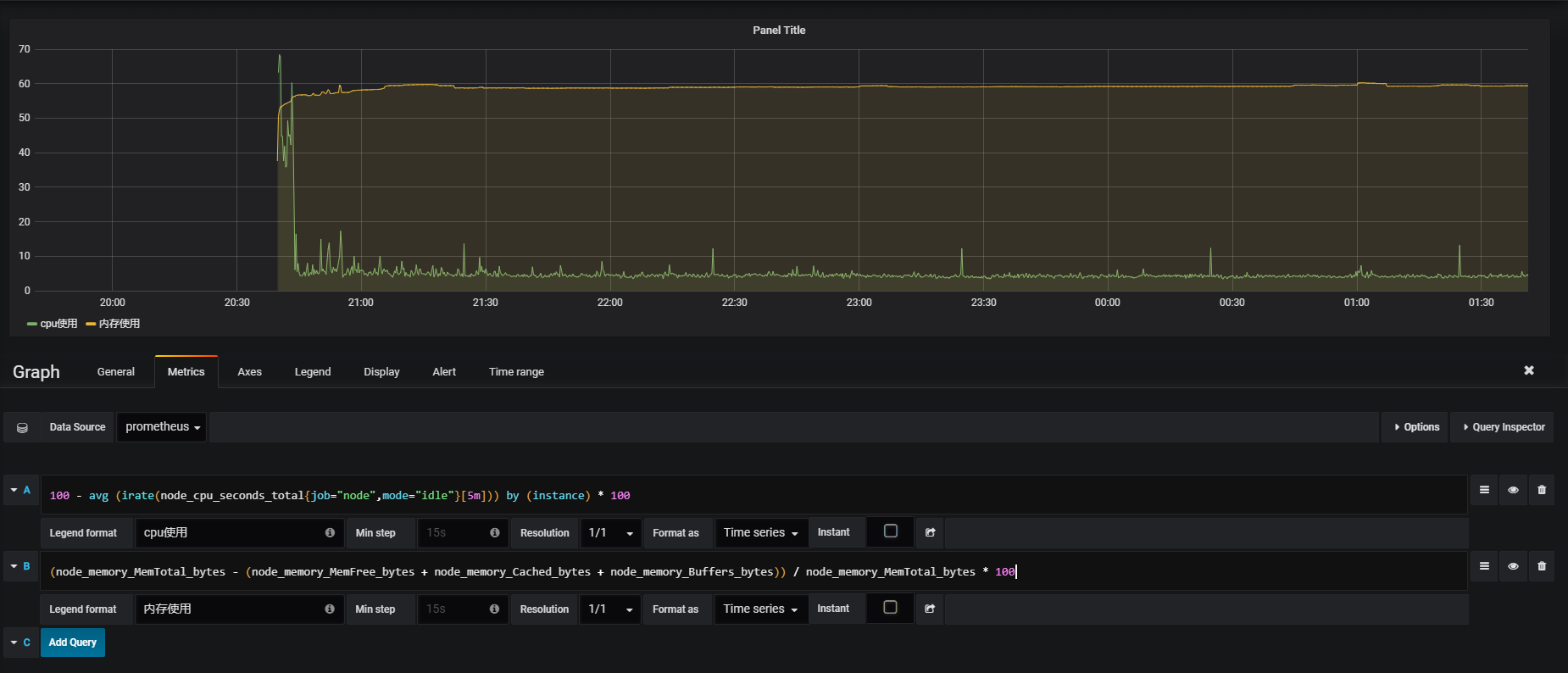
文中可能会有不少错误,欢迎提出.
原书的内容更为详尽和丰富,有兴趣的可以阅读原书.
参考资料:
https://prometheus.io/docs/prometheus/latest/getting_started/
https://github.com/prometheus/node_exporter
https://github.com/google/cadvisor
https://legacy.gitbook.com/book/songjiayang/prometheus/details