本文内容主要翻译自Reactive Systems Architecture第一章1.9节。
在分布式系统中,有组件发生故障造成对应服务失败是很平常的一件事。这里简单阐述一下在发生这些错误时的一些常用处理模式。
失败控制(failure control)的一个目标是在系统或他的一部分失败的情况下如何实现期望的一致性和传递保证。在部分系统失败的情况下,不影响到系统其他部分的稳定性。
但通常工程师不会意识到失败是很自然的一件事。
- 只是记录异常log 如果log不被人处理就一直保持失败
- 一个服务持续的失败可能导致来自于其他服务的过度重试,导致该服务被压垮,也可能造成依赖他的服务的级联失败。
- 每个服务都有性能限制,过度访问会造成服务失败(DoS).
下面简单介绍一下一些失败处理的方式
隔离和挡板(Isolation and bulkheading)
隔离失败 让失败不影响到其他系统
系统组件不要过度耦合
Hystrix
背压Backpressure
生产者根据消费者的消费步调来调整自己的生产速度
一般采用消费者(服务器)去获取内容(队列里面拿请求) 而不是生产者(客户端)去推送到消费者(服务器)
Akka Streams
Apache Spark Streaming
简单点的做法是用限流(RateLimiter)的方式 丢弃多余的请求
监督者(Supervision)
模块都会有一个监督者
组件挂了对应的监督者会收到通知 监督者会应用指定的策略去处理失败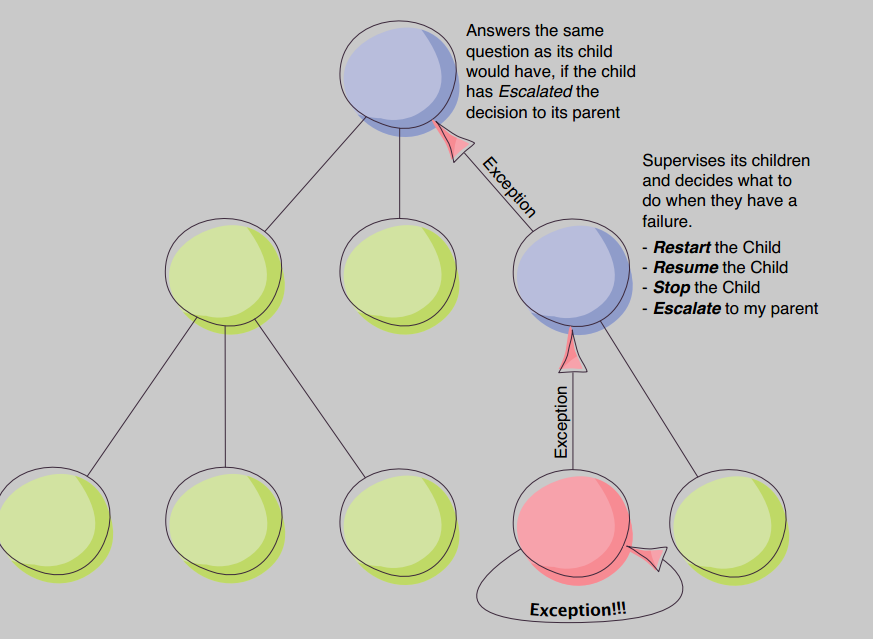
Akka
断路器(Circuit breaker)

关闭状态:调用失败或超时会让失败计数增加 成功的调用置零计数器 当达到最大的失败次数时 断路器切换为打开状态
打开状态:所有调用立即返回失败(断路) 避免给挂了的服务增加额外压力,造成联机(比如大量调用超时 浪费客户端资源)失败。在经过配置时间之后 切换为半开状态
半开状态:放开一个调用查看是否成功 成功了切换至关闭状态。
部分执行(Partial execution)
调用几个方法完成指定工作,其中有几个调用失败的情况。
有以下的一些处理方式:
事务保证: Atomic Broadcast 2PC
日志保证:journalling或write ahead log
事务补偿
服务降级(Service level degradation control)
系统出错时大多数工程师会返回错误,这常常会导致服务的不可用。
通过提供部分的服务可用可以降低服务直接不可用的开销。
fallback策略
参考链接:
https://www.cnblogs.com/iceTing/p/6238207.html
https://www.safaribooksonline.com/library/view/reactive-systems-architecture/9781491980705/