这次的笔记主要记录一下kafka的生产者的使用和一些重要的参数。
文中主要截图均来自kafka权威指南
主要涉及到两个类KafkaProducer和ProducerRecord.
总览
生产者的主要架构如下: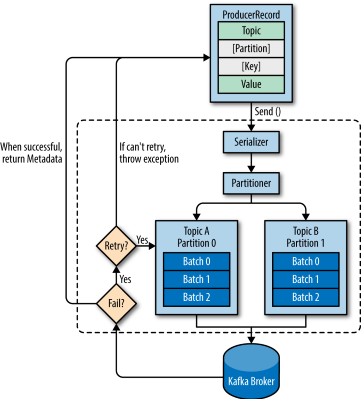
首先创建了一个ProducerRecord
进行序列化 kv变为ByteArray
进入Partitioner 如果之前指定了分区 那这一步什么都不会做
接着将Record放入要被发送到的同样的topic和分区的batch中
另一个单独的thread会进行发送操作
发送成功会返回RecordMetadata(包含topic 分区 偏移量)
失败的话会返回错误 producer会重试几次(retries配置)直到成功或者放弃返回错误
构造Kafka Producer
示例代码如下:
Properties properties = new Properties();
properties.put("bootstrap.servers", "192.168.56.101:9092");
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("metadata.fetch.timeout.ms", 5000);
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(properties);
ProducerRecord<String, String> record = new ProducerRecord<String, String>("CustomerCountry",
"Precision Products", "France");
Future<RecordMetadata> f = producer.send(record);
返回的是一个Future,有以下处理方式:
- 不在乎异常 可以不处理
- 直接get拿到结果 同步的获取方式
另外send方法也支持传入回调的方式进行异步处理
bootstrap.servers
指定了要连接到的broker,可以用,分隔写入多个,连接broker cluster时不需要写入全部的broker地址,broker本身会同步其他broker的信息,但最少放两个以免写一个对应的broker挂了。
在实际使用中,可能会出现org.apache.kafka.common.errors.TimeoutException: Failed to update metadata after 60000 ms.这个错误,请求本身是发送成功的,检查zk topic也建立了,但就是获取不到metadata。
这是因为填入的broker服务器和kafka在zk上注册的host不一致导致的(在zk上可以通过get /brokers/ids/{id}查看),可以通过修改kafka的server.properties的advertised.host.name和advertised.port改正。
但是要注意hosts文件会影响,比如配置了自己ip到一个域名上导致失败,注意代码在运行时log打出的实际的值。
例如电脑上装了银联控件,结果把localhost映射到了一个奇怪的地址:
例子中已经改为了ip。
另外实验环境也迁移至了虚拟机上,上一节用bash on windows搭建好的环境不知道为什么无论怎么改都获取不到metadata
key.serialization
用来指定key的序列化器(下面会提到)
配置Producers
文档:http://kafka.apache.org/documentation.html#producerconfigs
因为用的是0.9.0.1,一些参数在最新版已经被弃用了,自己使用多注意下。
这些的默认配置在ProducerConfig的static块中定义:
static {
CONFIG = new ConfigDef().define(BOOTSTRAP_SERVERS_CONFIG, Type.LIST, Importance.HIGH, CommonClientConfigs.BOOSTRAP_SERVERS_DOC)
.define(BUFFER_MEMORY_CONFIG, Type.LONG, 32 * 1024 * 1024L, atLeast(0L), Importance.HIGH, BUFFER_MEMORY_DOC)
.define(RETRIES_CONFIG, Type.INT, 0, between(0, Integer.MAX_VALUE), Importance.HIGH, RETRIES_DOC)
.define(ACKS_CONFIG,
Type.STRING,
"1",
in("all", "-1", "0", "1"),
Importance.HIGH,
ACKS_DOC)
... ...
这里列举一下比较重要的参数:
ACKS
指定一次写成功需要多少个分区分片必须收到record
0
不会等待broker的返回 不会知道是否成功 高吞吐1
接受leader的 比0安全 但也会有还来不及复制leader就挂掉等导致失败的情况all
所有的复本都接收到消息并回应 最安全的模式 但相对的延迟就比较惨了
默认值为1
BUFFER.MEMORY
缓存等待发送的消息
如果超过了 会在抛错前等待max.block.ms秒
默认32M
COMPRESSION.TYPE
默认是none 不压缩
可以是snappy gzip lz4
snappy用较少的cpu完成还行的压缩 性能和网络带宽的权衡
gzip是使用更多的cpu和时间但是压缩更好 网络带宽是主要限制时使用
RETRIES
重试次数 默认是0
默认间隔100ms (通过retry.backoff.ms控制)
不是所有的错误都会重试(RetriableException)
不要在业务里做重试
BATCH.SIZE
多个record被发送到同一个分区的时候 producer会进行批处理
内存 默认16k
满了就发 但不意味着只有满了才会发(见下一个参数)
设太大不会导致他的延迟 只不过会用更多的内存
设太小就惨了 会导致过于频繁
LINGER.MS
在发送当前batch时等多久额外的信息
默认是0
producer会在batch满了或者这个时间到了发送 默认是0就意味着即时发送
大于0会导致延迟 但是增加吞吐量
CLIENT.ID
任何字符串 自己定义 用来打log和metrics
MAX.IN.FLIGHT.REQUESTS.PER.CONNECTION
可以设置可以发送多少个请求不等回应 也就是允许同时有多少条消息在空中飞
默认是5
设大了会增加内存使用 但是提高吞吐
设过大了会导致降低吞吐 因为batch变得低效了
设置成1可以保证消息即使是在重试下也有序(下面顺序保证中提到)
TIMEOUT.MS, REQUEST.TIMEOUT.MS, METADATA.FETCH.TIMEOUT.MS
第1和第3在0.11.0.1版本中被移除了。。可以参考旧文档
第2 从服务端等待多久回应(默认30s)
MAX.BLOCK.MS
在send()和显式通过partitionsFor()请求元数据中间等待的时间
在send buffer满了 以及metadata没返回阻塞
MAX.REQUEST.SIZE
一次请求的数据大小限制(限制最大的消息 以及批处理的大小)
默认1M 意味着可以同时发1000条1K的消息 或者发一条1M的消息
注意上一节broker里也有自己的配置 最好两个配置相匹配
RECEIVE.BUFFER.BYTES SEND.BUFFER.BYTES
前者默认32K
后者默认128K
TCP发送和接受的buffer 用于socket写入和读取数据
设置为-1是用OS默认的设置
不同数据中心间可以适当提高点这个值因为网络环境会更差
顺序保证
kafka保证在一个分区里消息的顺序
上述可以发现 如果设置了max.in.flights.request.pre.connection大于1(默认5)
并且retries大于0(默认0)那就完蛋了
可能写给同一个分区第一条消息写入失败 进入retry
但第二条写入成功
建议设置per.connection为1 但这会严重限制吞吐 只用于顺序很重要的场合
序列化
自定义可以自己实现org.apache.kafka.common.serialization.Serializer接口。
使用Apache Avro
优点:
- 语言中立的序列化格式
- 兼容性
用于写和读的schema必须兼容
反序列化器必须能够访问用于写数据的schema
保存每个record的schema开销很大(通常是两倍于record)
可以将schema保存在一个注册器中管理 只需要在消息中写入对应的id
Schema Registry - 有很多开源的选项 可以使用confluent platform
文档: http://docs.confluent.io/current/schema-registry/docs/index.html
这个可以单独记一个笔记,等实践后再做整理。
分区
如果key为null并且默认的分区器被使用 会用round-robin来平衡
有key 默认的分区器会hash key(自带的hash算法) 因为要保证同一个key总是写入同样的分区 他会使用所有的分区(不管是否可用) 写到不可用的会报错
如果分区数改变了 映射关系就会改变 同样的key在之后可能会到其他分区中
所以预先确定分区的数量在这种i情况下比较重要